Lora
Lora 模型是一种轻量级的微调方法,可以通过少量的图片训练出一个小模型,然后和大模型结合使用,干涉大模型产生的结果。
Lora 模型可以在 t2i 和 i2i 模式下使用,可以和任何主模型一起使用。
Lora 的模型文件后缀一般是 .pt 或者 .safetensors.
使用 Lora 模型
在扩展标签页安装 Lora 模型加载插件,然后将你的 Lora 模型放到 stable-diffusion-webui/models/lora 路径下。比如 幻星集塔罗牌 LoRA.
重启 WebUi,然后在 SD(Sketch Design)的文生图或图生图界面内,点击生成按钮下的粉色图标,即“additional networks”选项卡。在弹出的面板中选择“Lora”选项卡。
然后点击想要应用的 Lora 模型,它将被添加到提示语中,其格式为 <lora: 数字>,数字代表 Lora 模型的权重,默认为 1。
接下来点击“生成”按钮开始生成图片。
当生成完成后,将鼠标移动到 Lora 卡片的左下角或标题上方,会出现“替换预览”的红色文字。点击此处即可将刚生成的图片设置为此 Lora 模型的预览图。
训练 Lora 模型
训练的流程主要分为 预处理图片,标注图片,训练模型 三个步骤。其中预处理图片就是挑选高质量图片的过程,而标注图片就是给每个图片配发对应文字。
这里我们以流行的 Kohya’s GUI 作为参考展开讲解:
准备
首先,为了训练自己的 Lora 模型,我们需要准备以下工具和素材:
- 一台拥有足够显存(至少 8GB)的电脑;
- 至少 100 张你想要的风格图片放在同一个文件夹中;
- 一个基础模型,如 stable-diffusion-v1-5 或 ChilloutMix;
接下来,按照以下步骤进行操作:
- 安装 Python 3.10,并将其添加到 PATH 环境变量中。
- 安装 Git 和 Visual Studio 2015、2017、2019 和 2022 redistributable。
- 运行 PowerShell 以管理员身份运行,并执行
Set-ExecutionPolicy Unrestricted命令以激活脚本运行权限。
安装训练程序
首先下载 kohya_ss
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
python -m venv venv
.\venv\Scripts\activate
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --use-pep517 --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
accelerate config
(可选)安装 CUDNN 8.6
可提高 NVIDIA 30X0/40X0 的训练速度。如果您需要安装它,请下载 cudnn_windows 文件并解压缩到该存储库的根目录下。然后运行以下命令:
.\venv\Scripts\activate
python .\tools\cudann_1.8_install.py
启动 GUI
针对 kohya_ss,这里有两种方法启动 GUI,一种是通过 bat 脚本,一种是通过 Python 程序。
gui.bat --listen 127.0.0.1 --server_port 7860 --inbrowser --share
.\venv\Scripts\activate
python.exe .\kohya_gui.py
运行后应该会出现下面的界面:
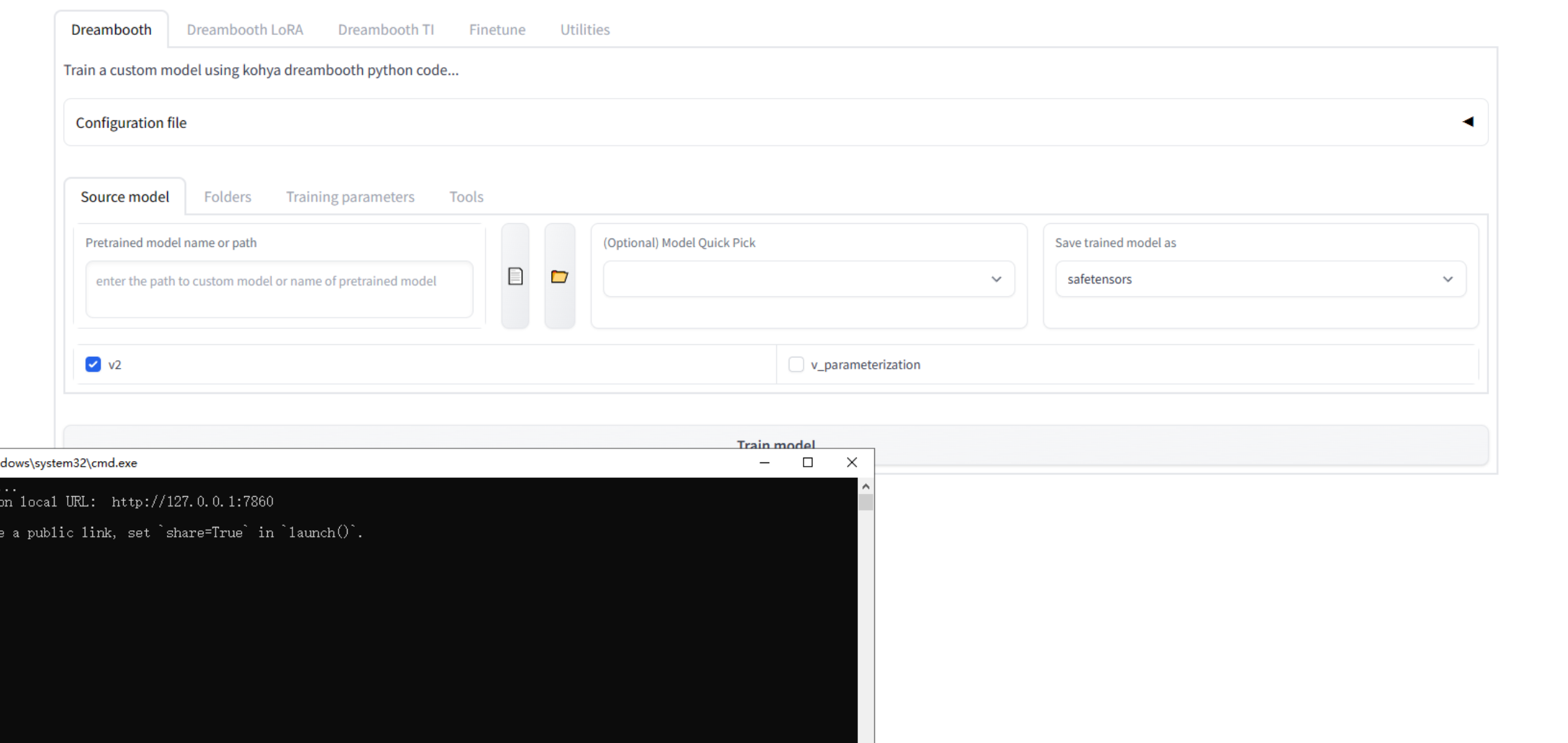
数据集准备
- 准备照片
准备合适的照片。训练角色 lora,图片可以不多但是质量要高,并且每张图做好尺寸调整,你可以通过 Brime 或者 WebUi 自带的图片处理选项卡处理图片,尺寸必须是 64 的倍数 。如果你的显卡性能不足,推荐仅裁切为 512x512 尺寸的。3
- 标注图片
标注图片即将图片和同名 txt 文件放在一起,txt 文件中写上图片对应的提示词。
train01.jpg
train01.txt -> 里面是图片的描述
我们可以利用 WebUi 的 训练 选项卡中 图像预处理 标签页为每个图片自动生成标签。(记得勾选使用 Deepbooru)。
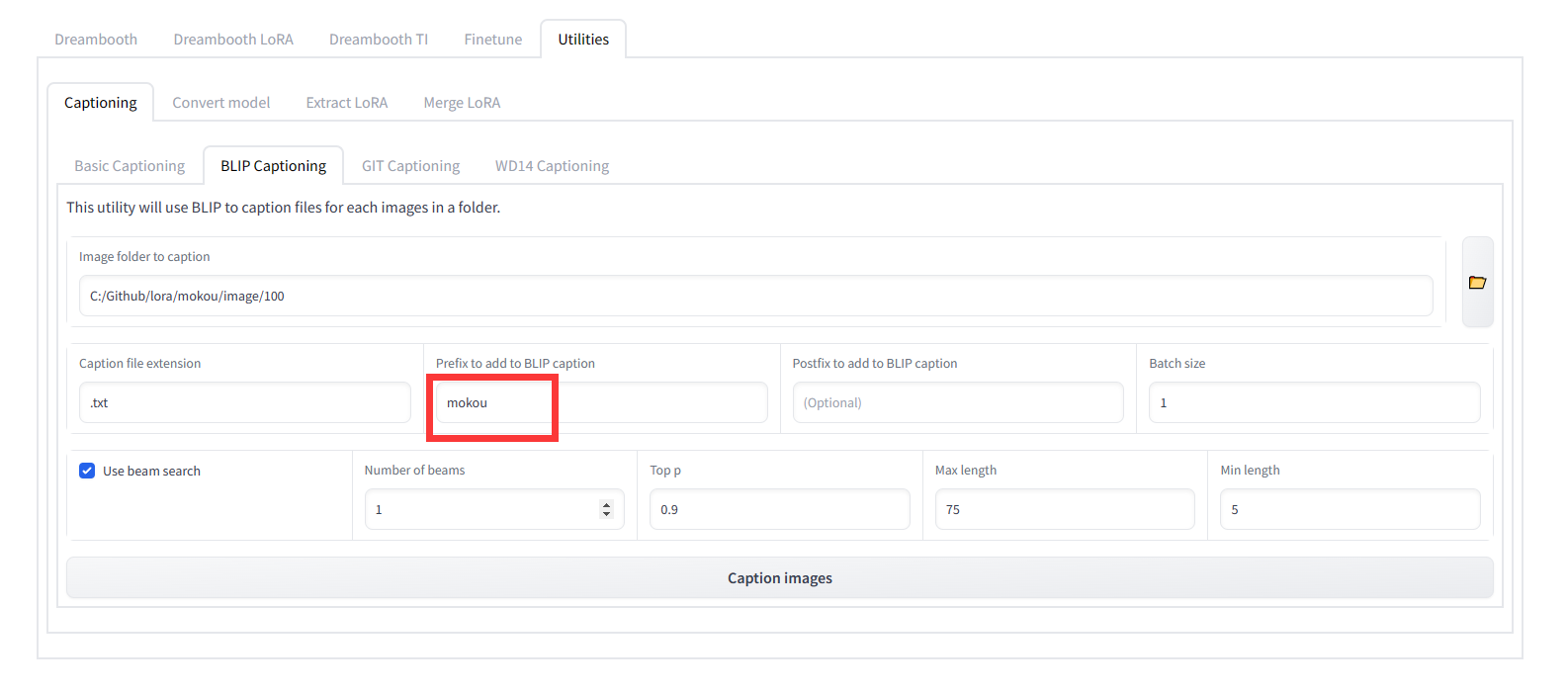
如果你使用 kohya-ss 的话,也可以在在 Utilities 标签页中使用 Captioning 功能。
如果你需要训练新概念,比如新的人物,请在图片的标注信息中去掉和它很相近的名字。比如训练 LoveEyes,那么请在标注中去掉 Eyes。
现在你应该有了数据集。如果你没有,可能是 Danbooru 模型下载失败,请更换网络重试。
对于 Kohya GUI 用户,放置数据集请新建一个 Lora 文件夹,然后创建 image log model 三个文件夹。然后在 image 文件夹中新建一个文件夹 100,也就是训练 100 次。放入你处理好的照片。
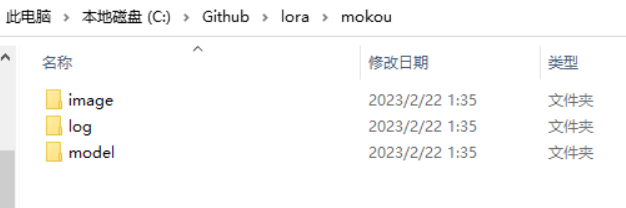
对于使用 lora-scripts 的用户,你的数据集应该这样放置:

然后你的文件夹结构应该是下面这样的:
lora_dataset
|
|--num_Concept
|--train01.jpg
|--train01.txt -> 里面是图片的描述
num_Concept 代表 {重复次数}_{概念名字},{} 代表未知量。
训练
先关闭占用显存高的程序,准备训练。
Gui
在 GUI 中,你可以指定要使用的基础模型和风格图片文件夹,配置相关参数,如 source model(基础模型),batch size(并行数量),network dim(网络大小),learning rate(学习率)等。等待训练完成,您可以在输出文件夹中找到生成的 Lora 模型文件(以。safetensors 为后缀)。如果失败的话,可以先取消勾选 Use 8bit adam 再试一次。
Scripts
对于使用 lora-scripts 的用户,请修改 train.sh 的参数来调整训练:

https://github.com/Akegarasu/lora-scripts/blob/main/train.sh
底模路径就是大模型的路径地址,训练数据集路径就是
lora_dataset/num_Concept
num_Concept2
max_train_epoches 参数一般 20 即可,resolution 参数就填写你裁切图片时候使用的尺寸参数即可。学习率默认即可。
batch_size 就是单批次并行处理的图片数量。2
点击开始训练,然后在结果文件夹就可以找到模型就好了。
在扩展标签页安装 Lora 模型加载插件,然后将 Lora 模型文件放到 stable-diffusion-webui/models/lora 路径下,并重新启动 SD WebUi。然后就可以按照之前的步骤,在 SD WebUi 中使用您的 Lora 模型生成图片。
AutoDL
AutoDL 在线训练镜像:https://www.bilibili.com/read/cv21450198
LoRA 在线云端训练教程 AutoDL https://www.bilibili.com/read/cv21450198
其他
LoRA: Low-Rank Adaptation of Large Language Models 简读
Created: January 17, 2023 04:35:23