帮助
https://www.bilibili.com/video/BV1A8411775m/
术语
| 缩写/写作术语表 | 解释 |
|---|---|
| oneshot | 一张图 |
| LAION | 一个图像数据集库,https://laion.ai |
| aug | augmentaion, 通过裁切,翻转获取更多数据集的方式 |
| ucg | unconditional guidance |
| ML | 机器学习 |
| LatentSpace | 潜在空间 |
| LDM | Latent Diffusion Model 潜在扩散模型 |
| Stable Diffusion | 稳定扩散 |
| 超分 | 一般指使用 Ai 技术提升图片分辨率,提高清晰度 |
| 黑话 | 解释 |
|---|---|
| NAI | (Novel AI,一般特指 Leak) |
| 咒语 | prompts |
| 施法/吟唱/t2i | Text2Image |
| 魔杖 | t2i/i2i 参数 |
| i2i | Image2Image, 一般特指全部图片生成 |
| inpaint | i2i 一种 maskredraw,可以局部重绘 |
| ti/emb/炼丹 | Train 中的文本反转,一般特指 Embedding 插件 |
| hn/hyper/冶金 | hypernetwork,超网络 |
| 炸炉 | 指训练过程中过度拟合,但炸炉前的日志插件可以提取二次训练 |
| 废丹 | 指完全没有训练成功 |
| 美学/ext | aesthetic_embeddings, emb 一种,特性是训练飞快,但在生产图片时实时计算。 |
| db/梦展 | DreamBooth,目前一种性价比高(可以在极少步数内完成训练)的微调方式,但要求过高 |
| ds | DeepSpeed,微软开发的训练方式,移动不需要的组件到内存来降低显存占用,可使 db 的 vram 需求降到 8g 以下。开发时未考虑 win, 目前在 win 有兼容性问题故不可用 |
| 8bit/bsb | 一般指 Bitsandbyte,一种 8 比特算法,能极大降低 vram 占用,使 16g 可用于训练 db。由于链接库问题,目前/预计未来在 win 不可用 |
Stable Diffusion 如何工作
推理过程

information creator 完全在图像信息空间(或潜伏空间)中工作。这一特性使它比以前在像素空间工作的扩散模型更快。在技术上,这个组件是由一个 UNet 神经网络和一个调度算法组成的。
Text Encoder
提示词的解析由 Text Encoder/CLIP 处理 (token embedding),这里是提示词转译给 AI 的关键一步。
文本编码器负责将输入的提示转换为 U-Net 可以理解的嵌入空间。它通常是一个简单的基于变换器的编码器,将一连串的输入标记映射到一连串的 latent text-embeddings 中。
稳定扩散使用 ClipText 用于文本编码。输入文本,输出 77 个标记嵌入向量,每个都有 768 个维度。
information creator
UNet + Scheduler(也就是采样算法)在潜在空间中逐步处理/分散信息。
它输入文本嵌入和一个由噪声组成的起始多维数组(结构化的数字列表,也叫张量),输出一个经过处理的信息阵列。
Image Decoder
Text Decoder 根据从 information creator 那里获得的信息绘制一幅图画。 它只在过程结束时运行一次以生成最终图像。
autoencoder(VAE) 模型有两个部分,一个编码器和一个解码器。编码器用于将图像转换为 latent representation,作为 U-Net 模型的输入。解码器则将 latent representation 转回图像。
在推理过程中,使用 VAE 解码器将反向扩散过程产生的去噪潜像转换回图像。在推理过程中,我们只需要 VAE 解码器。
Autoencoder Decoder(VAE) 使用处理过的信息阵列绘制最终图像的解码器。输入处理过的信息阵列 (dimensions: (4, 64, 64)),输出结果图像 (dimensions: (3, 512, 512),即 (red/green/blue, width, height)。
CLIP 的工作
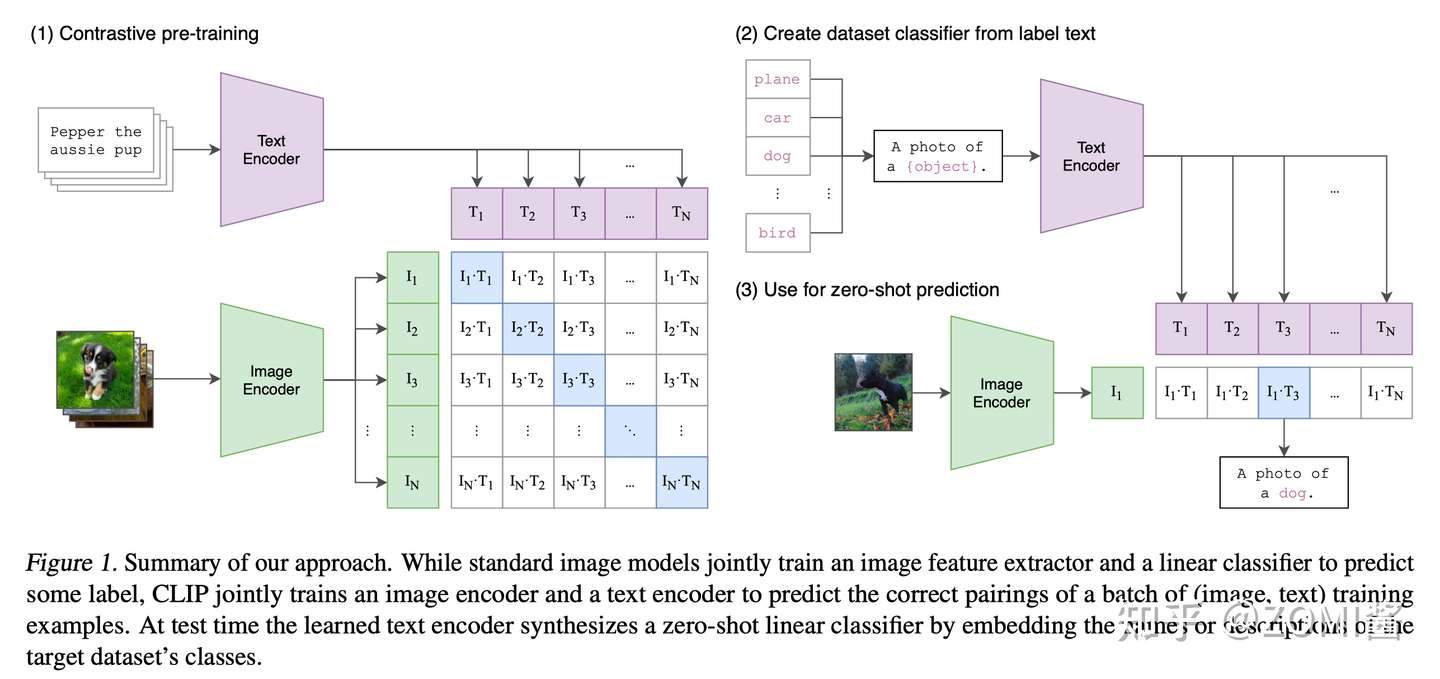
CLIP 训练图 from https://bbs.huaweicloud.com/blogs/371319
流程
Stable Diffusion 中使用的自动编码器的缩减系数为 8。这意味着一张 (4, 512, 512) 的图像在潜在空间中是 (4, 64, 64)。
在使用稳定扩散推理一张 512 x 512 的图片的过程中,模型用一个种子和一个文本提示作为输入。潜在种子生成大小 64 × 64 的随机潜在图像,而 prompt 进入 Text Encoder 通过 CLIP 的文本编码器转化为大小为 77 × 768 的文本嵌入。
U-Net 在以文本嵌入为条件的同时迭代地对随机高斯噪声表示进行去噪。U-Net 通过 采样算法 计算去噪的潜在图像表示,输出噪声残差。这个步骤重复许多次后,潜在表示由 Image Decoder 的 auto encoder 的解码器解码输出。

扩展
WebUi 的预处理
WebUi 的 prompt_parser 通过本地 WebUi 实现了 Prompt editing 等功能。
WebUi prompt 语法会转换为相应时间的 prompt, 然后通过 embedding 交给 Ai 处理。
关于权重的实现
- 权重增加通常会占一个提示词位。
关于交叉注意力控制的实现
- 到了指定 Step ,WebUi 程序会替换对应 提示词,达到交叉注意力控制效果。
其他以此类推。
整个看下来,原理流程如图
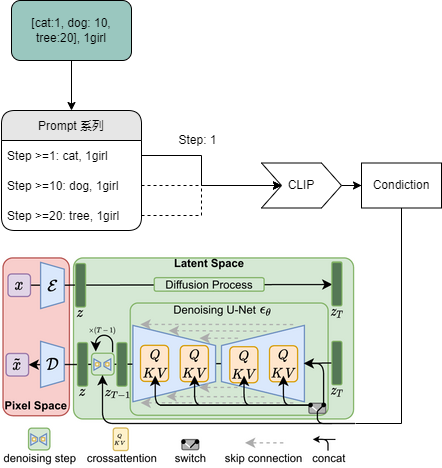
By RcINS
数学知识
How diffusion models work: the math from scratch
名词
overfitting 过拟合
Creating a model that matches the training data so closely that the model fails to make correct predictions on new data.
创建的模型与训练数据过于匹配,以致于模型无法根据新数据做出正确的预测。
收敛 (convergence)
通俗来说,收敛通常是指在训练期间达到的一种状态,即经过一定次数的迭代之后,训练损失和验证损失在每次迭代中的变化都非常小或根本没有变化。也就是说,如果采用当前数据进行额外的训练将无法改进模型,模型即达到收敛状态。在深度学习中,损失值有时会在最终下降之前的多次迭代中保持不变或几乎保持不变,暂时形成收敛的假象。
VAE
Variational autoencoders (VAEs) 是一种用于学习潜在表示的深度学习技术。它们也被用来绘制图像,在半监督学习中取得最先进的成果,以及在句子之间进行插值。2
CFG
这个词汇为 Classifier Free Guidance Scale 的缩写,用于衡量模型 生成的预期图片和你的提示保持一致的 程度。 Cfg Scale 值为 0 时,会生成一个基于种子的随机图像。
打个比方,想象你的提示是一个带有可变宽度光束的手电筒,你将它照到模型的潜在空间上以突出显示特定区域——你的输出图像将从该区域内的某个地方绘制,具体取决于种子。1
将 Cfg Scale 拨向 零会产生极宽的光束 ,突出显示整个潜在空间——您的输出几乎可以来自任何地方。
将 Cfg Scale 拨向 20 会产生非常窄的光束, 以至于在极端情况下它会变成激光指示器,照亮潜在空间中的一个点。
Loss functions
在优化算法的上下文中,用于评估候选解决方案(即一组权重)的函数称为目标函数。 4
对于神经网络,我们寻求最小错误。 因此,目标函数通常被称为成本函数或损失函数,由损失函数计算的值简称为“loss”。
损失函数。3
关于 Loss Function 的中文解释请读 损失函数
潜在空间
压缩数据的表示,其中相似的数据点在空间上更靠近在一起。5
关于潜在空间的中文解释请读 理解机器学习中的潜在空间.
损失
一种衡量指标,用于衡量模型的预测偏离其标签的程度。或者更悲观地说是衡量模型有多差。要确定此值,模型必须定义损失函数。例如,线性回归模型通常将均方误差用于损失函数,而逻辑回归模型则使用对数损失函数。6
Hyperparameter
超参数
机器学习算法的参数。 示例包括在决策林中学习的树的数量,或者梯度下降算法中的步长。 在对模型进行定型之前,先设置超参数的值,并控制查找预测函数参数的过程,例如,决策树中的比较点或线性回归模型中的权重。 有关详细信息,请参阅 Wikipedia.
Pipeline
要将模型与数据集相匹配所需的所有操作。 管道由数据导入、转换、特征化和学习步骤组成。 对管道进行定型后,它会转变为模型。7
epoch
在训练时,整个数据集的一次完整遍历,以便不漏掉任何一个样本。因此,一个周期表示(N/批次规模)次训练迭代,其中 N 是样本总数。6
batch size
一个批次中的样本数。例如,SGD 的批次规模为 1,而小批次的规模通常介于 10 到 1000 之间。批次规模在训练和推断期间通常是固定的;不过,TensorFlow 允许使用动态批次规模。6
iteration 迭代
模型的权重在训练期间的一次更新。迭代包含计算参数在单个批量数据上的梯度损失。6
Tensor
TensorFlow 程序中的主要数据结构。张量是 N 维(其中 N 可能非常大)数据结构,最常见的是标量、向量或矩阵。张量的元素可以包含整数值、浮点值或字符串值。
checkpoint
一种数据,用于捕获模型变量在特定时间的状态。借助检查点,可以导出模型权重,跨多个会话执行训练,以及使训练在发生错误之后得以继续(例如作业抢占)。请注意,图本身不包含在检查点中。6
embeddings
一种分类特征,以连续值特征表示。通常,嵌入是指将高维度向量映射到低维度的空间。例如,您可以采用以下两种方式之一来表示英文句子中的单词:
- 表示成包含百万个元素(高维度)的稀疏向量,其中所有元素都是整数。向量中的每个单元格都表示一个单独的英文单词,单元格中的值表示相应单词在句子中出现的次数。由于单个英文句子包含的单词不太可能超过 50 个,因此向量中几乎每个单元格都包含 0。少数非 0 的单元格中将包含一个非常小的整数(通常为 1),该整数表示相应单词在句子中出现的次数。
- 表示成包含数百个元素(低维度)的密集向量,其中每个元素都包含一个介于 0 到 1 之间的浮点值。这就是一种嵌套。
在 TensorFlow 中,会按反向传播损失训练嵌套,和训练神经网络中的任何其他参数时一样。6
激活函数
一种函数(例如 ReLU 或 S 型函数),用于对上一层的所有输入求加权和,然后生成一个输出值(通常为非线性值),并将其传递给下一层。6
weight
线性模型中特征的系数,或深度网络中的边。训练线性模型的目标是确定每个特征的理想权重。如果权重为 0,则相应的特征对模型来说没有任何贡献。6
ENSD
ENSD 是 eta 噪声种子增量,它改变了种子。
NAI 使用 31337
CLIP
CLIP 是一种非常先进的神经网络,可将提示文本转换为数字表示。对一个相对复杂场景的文本描述,AI 需要能“理解”并匹配到对应的画面,大部分项目依赖的都是一个叫 CLIP 的模型。
CLIP 在生成模型的潜在空间进行搜索,从而找到与给定的文字描述相匹配的潜在图像,它非常现代且高效。
ignore-last-layers-of-clip-model
WebUi 使用的是 clip-interrogator 项目,它结合了 blip 和 clip 项目,很大地优化 图像到文本 的过程。blip 负责从原图片中解读文本,由 clip 负责解读适合创作的新图像的描述。
CUDA
配合 CUDA 技术,显卡可以模拟成一颗 PhysX 物理加速芯片。
创建日期: 2022年10月13日 10:24:49